Groups and subhalos
Group finding is a basic analysis task of cosmological simulations of structure formation. GADGET-4 contains parallel algorithms for finding virialized dark matter halos and their embedded gravitationally bound subhalos which can be run both on the fly and in postprocessing. The group finders may also be applied to particle data accumulated directly on past backwards lightcone. In the following, a basic description of the storage format is given, which is largely identical with the one introduced in AREPO in the context of the Illustris and IllustrisTNG projects (note that read-scripts from the data-releases of these two projects may thus be easily adapted for� GADGET-4 usage, too).
FOF and SUBFIND
Group finding in GADGET-4 is supported through two main algorithms, the classic friends-of-friends (FOF) approach to find groups of particles of approximately virial overdensity, and the SUBFIND algorithm to identify gravitationally bound substructures in these groups in configuration space. SUBFIND hence relies on FOF, and in can only be used if also FOF is enabled. Furthermore, there is the SUBFIND_HBT variant of SUBFIND which identifies the substructure candidates based on past membership in gravitationally bound subhalos.
In case group finding is enabled, the snapshot output of GADGET-4 will occur in group order. Specifically, the particles in the output files will appear in the order of the group catalogue itself, giving them the following logical structure:
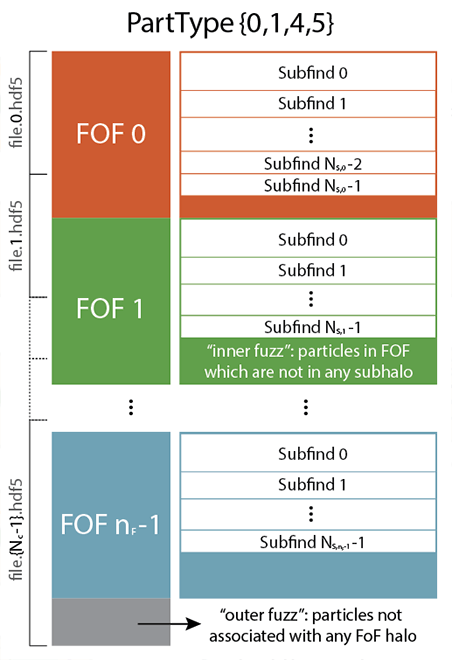
In case the HDF5 output is used, the order is imposed individually on every particle type in its corresponding data set group. In the classic file format, it applies to each particle type individually as well (here each block in the snapshot contains the particle types jointly in type-order). If a snapshot is split over multiple files, the contents of these files in each dataset are treated logically as if they were concatenated in the order of the partial files. Note that individual groups are allowed to spill over across file boundaries.
The snapshot files first contain the particles found in FOF groups, and these groups are ordered descending in size. This means that the particle data begins with the particles contained in the largest FOF group. Normally, not all particles are contained in FOF groups above the imposed minimum threshold for the group particle number. The particles outside the resolved groups then come at the end of snapshot file.
Each FOF halo is decomposed by SUBFIND or SUBFIND_HBT into a set of disjoint gravitationally bound subhalos. They are nested inside the FOF group, again in an order of decreasing length. This means that the particles with the largest subhalo in a FOF group will come first, followed by the second largest subhalo, and so on. Within each subhalo, the particles are additionally sorted according to their binding energy, i.e. the most bound particle in a subhalo will come first. Since not all particles within a FOF group need to be part of a subhalo, the sequence of subhalo particles is in general followed by a set of particles that are members of the FOF group but are not gravitationally bound to any of the subhalos. There may also be no subhalo for a given FOF group at all, meaning that there is no gravitationally bound subset of particles in the FOF group above detection threshold.
Format of group catalogues
The structure and organization of the group catalogues is quite
similar to the snapshot files. They consist of different blocks that
are stored subsequently in the binary files corresponding to formats 1
and 2, and in different data groups called Header, Groups, and
Subhalos when HDF5 is selected. Like the snapshot files, the group
catalogues can be split over multiple files (in which they are stored
in separate groupdir_XXX directories), or they can be stored in a
single file. If they contain only FOF information, they start with the
basename fof_tab otherwise they start with the basename
fof_subhalo_tab.
The most important fields of the Header in the group catalogues are:
| Header Field | Type | HDF5 name | Comment |
|---|---|---|---|
| Ngroups | int64 | Ngroups_ThisFile | number of groups in this file |
| Nsubhalos | int64 | Nsubhalos_ThisFile | number of subhalos in the present file |
| Nids | int64 | Nids_ThisFile | number of particles in groups in this file |
| NgroupsTot | int64 | Ngroups_Total | total number of groups |
| NsubhalosTot | int64 | Nsubhalos_Total | total number of subhalos |
| NidsTot | int64 | Nids_Total | total number of particles in groups |
| NumFiles | int | NumFiles | number of subfiles of this catalogue |
| Time | double | Time | output time/scale factor |
| Redshift | double | Redshift | output redshift |
FOF catalogue
The information about the FOF groups consists of the following blocks. They are effectively a table with properties for each FOF group. Some of the fields are only present if the FOF halos have also been processed with SUBFIND, such as the number of subhalos contained in a FOF halo, for example.
| Nr | HDF5 Identifier | Fmt2-ID | Block contents |
|---|---|---|---|
| 1 | GroupPos | File header | |
| 2 | GroupVel | Particle positions | |
| 3 | GroupMass | Particle velocities |
To locate a certain FOF halo in the corresponding snapshot file, one has to get the offset from the beginning of the file for each particle type, and then skip fast forward in the snapshot file to the corresponding starting position. One can then start reading there, taking the number of particles for the reported group length. This is then the FOF halo.
SUBFIND catalogue
The SUBFIND catalogue extends the group catalogue with additional blocks (i.e. datasets) that give further information for each subhalo. The total length of these entries is equal to the total number of subhalos given in the Header, i.e. TotNsubhalos. The entries in the catalogue are as follows:
| Nr | HDF5 Identifier | Fmt2-ID | Block contents |
|---|---|---|---|
| 1 | SubhaloPos | File header | |
| 2 | SubhaloVel | Particle positions | |
| 3 | SubhaloMass | Particle velocities |
To read the particle data of an individual subhalo, one again needs to compute the correct file offset into the corresponding snapshot file. This is obtained here by first identifying the offset of the corresponding parent FOF group, and then computing an additional offset by summing up the lengths of all previous subhalos in the same FOF group. This needs to be done for each particle type separately. One can then skip towards the beginning of the corresponding subhalo and read the right number of particles there.