|
|
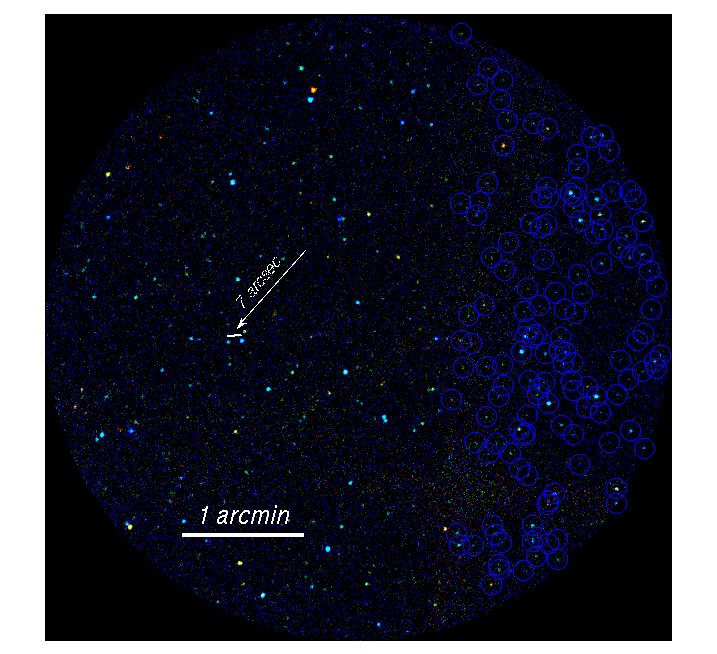
Fig.:
Deep 1Msec Chandra image of the Galactic plane region. The image is
constructed in three colours, photons of energies 0.5-1 keV are red,
1-3 keV green, 3-7 keV blue. The sources, which were detected in these
deep observations, are denoted by circles on a part of the image.
|
|  |
In the universe, highly energetic electromagnetical X-rays usually are
emitted by hot gas at a temperature of 10 to 100 million degrees. 25
years ago, astrophyisicsts found this kind of radiation along the disk
of our galaxy - with no plausible explanation available: The so called
”Galactic Ridge X-ray emission“ (GRXE) might be
characteristic for a very hot, optically thin plasma. However, an
interstellar medium with these thermal properties would ”fly
away“ from our galaxy immediately, causing a major energy loss
that can not be replenished by the energy sources in the Milky Way.
Also, attempts to explain the GRXE as result of interaction of cosmic
rays and the interstellar medium (ISM) could not be verified. In the
past years observations from X-ray satellites RXTE (Rossi X-ray Timing
Explorer) and Integral showed that the distribution of the GRXE
follows the same pattern as the stars in the Milky way. This led to
the assumption that the bulk of the X-ray emission originates from
stars, besides a small fraction being produced by hot, truly diffuse
interstellar plasma, heated by stellar explosions (supernovae).
These findings motivated the group around Mikhail Revnivtsev to
perform more precise tests with the Chandra X-ray Observatory. The
galactic test area they chose was a small field about half the
moon’s size near the center of the Milky Way. Explains
Revnivtsev: ”We chose a region of the Galactic plane that
provided good conditions to perform our measurements: In this area we
have a high GRXE intensity, which is essential to minimize the effects
of X-radiation from extragalactic sources. On the other hand, there is
a weak interstellar absorption of X-rays, crucial to maximise
Chandra’s sensitivity to discrete sources.“
Indeed Revnivtsev and his team succeeded in finding discrete point
sources for the GRXE focussing on a yet smaller ”high
resolution“ circle in the test area where Chandra’s
angular resolution is best. The scientists analysed the
telescope’s images, finding 473 radiation peaks in a small
circle of only ~2.6 arcminutes radius. In the next step the research
team proved that the results of this limited area can be applied to
the whole galaxy. They did so by scanning the same galactic area with
another telescope. The Spitzer telescope operates at the near infrared
(NIR) spectral band and is specialised to detect stellar mass
distribution. Then they put this value into relation to the measured
X-ray surface brightness and compared the result to the known GRXE/NIR
intensity ratio of the whole Milky Way. They found that the two values
were in perfect agreement. ”According to these results“,
says Revnivtsev, ”we can regard our present study of just a tiny
region of our galaxy as representative for the whole Milky Way.“
Most of the 473 X-ray sources detected are by all likelihood accreting
white dwarfs and binary stars with a high activity in their
coronae. White dwarfs are remnants of low-mass stars that accumulate
matter from their partner-stars in a binary system. The final
resolution of the diffuse GRXE-”cloud“ into discrete
source has far reaching consequences for our understanding of a
variety of astrophysical phenomena. ”Knowing the sources of GRXE
we have solved a major energy problem in our Galaxy“, resumes
Revnivtsev. ”Furthermore, we can use GRXE as a direct measure
for variations in stellar populations in our Milky Way. And it also
has become clear that, when studying external galaxies,
astrophysicists have to be aware that diffuse X-ray emission from
these objects will contain or even be dominated by radiation stemming
from stellar type sources like accreting white dwarfs and coronally
active stars.“
Barbara Wankerl (Public Outreach Coordinator, Exzellenzcluster ‘Universe’)
Further Information
 Press Release Cluster of Excellence ‘Universe’ Press Release Cluster of Excellence ‘Universe’
Press Release Max Planck Society
For further information please contact:
Barbara Wankerl
Excellence Cluster Universe
Technische Universität München
Tel.: +49 89 35831-7105
email: barbara.wankerl universe-cluster.de universe-cluster.de
Dr. Eugene Churazov
Max-Planck-Institut für Astrophysik, Garching
Tel.: +49 89 30000-2219
email: echurazovmpa-garching.mpg.de
|