 |
|
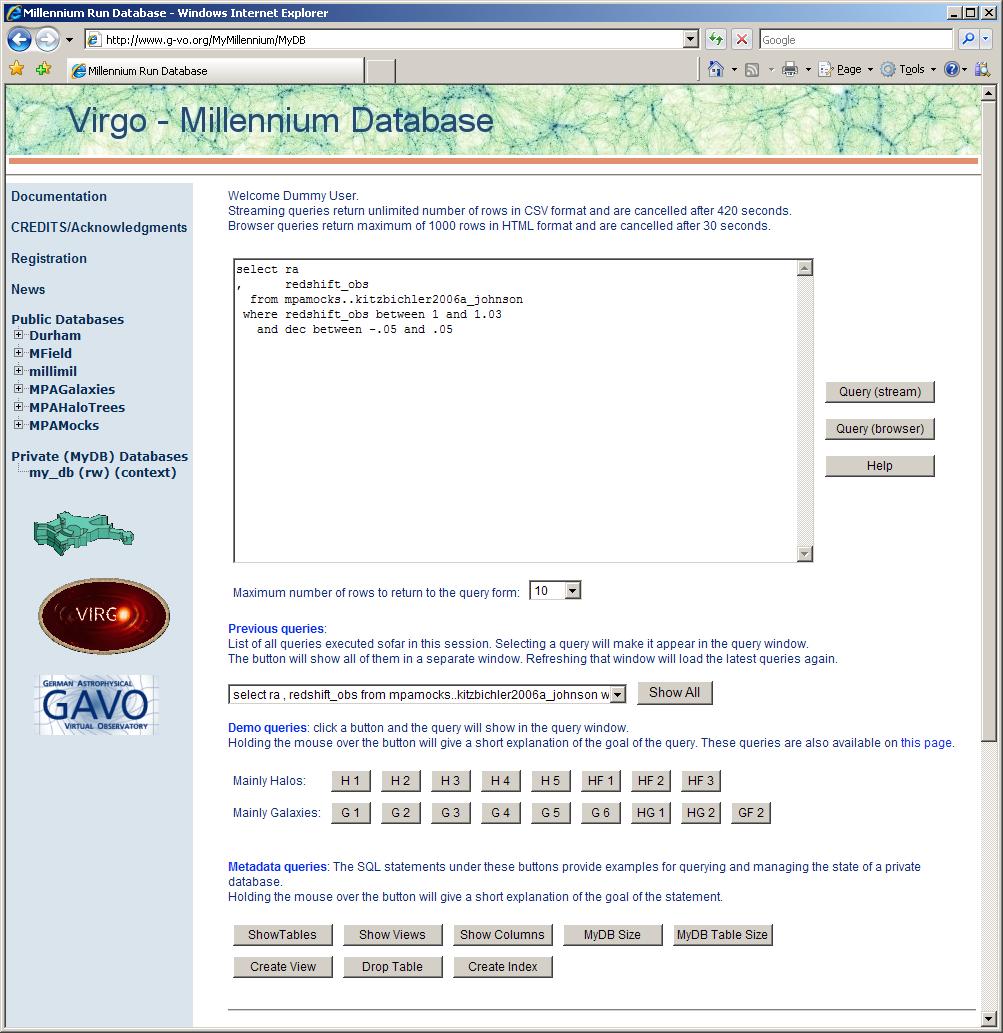
Fig. 1:
The web interface to the Millennium Simulation archie. The
query shown selects all galaxies with redshifts between 1.0 and 1.03
in a 0.1 degree slice in declination from a database containing a deep
mock survey of galaxies on a 1.4° × 1.4° area of the sky.
|
 |
 |
|
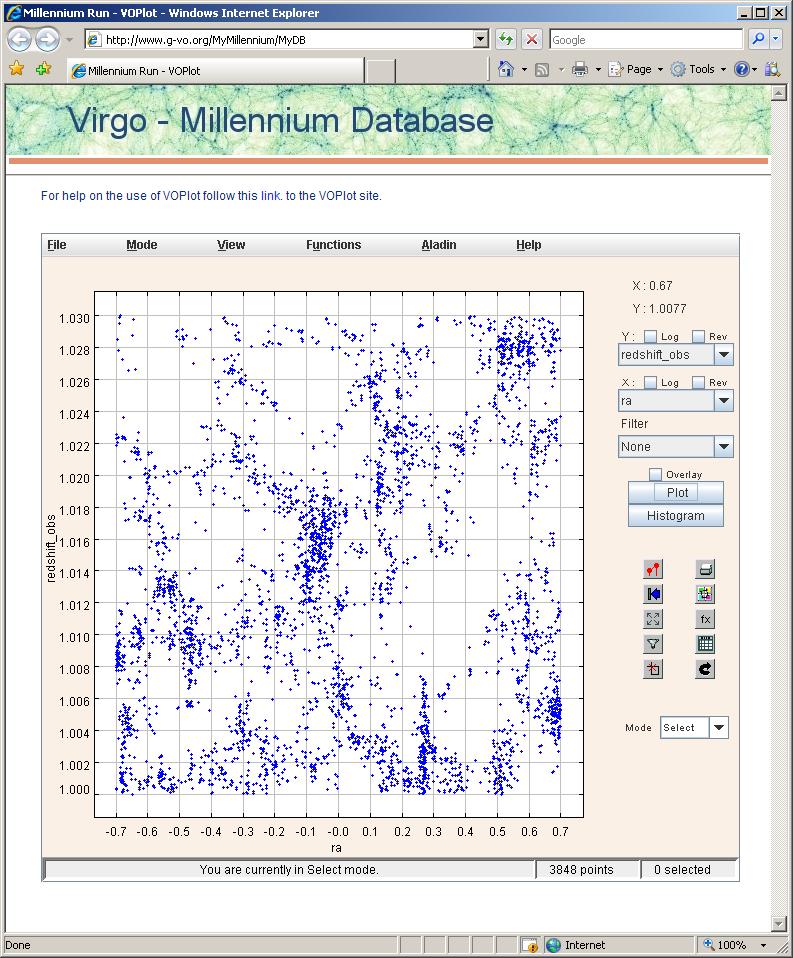
Fig. 2:
A plot made using the web-tool VOPlot of the positions in
redshift and right-ascension of the galaxies returned by the query of
Fig.1
|
| |
The public dissemination of a large and compex data set such as the
Millennium Run brings challenges which are different from and go
beyond those which must be faced when setting up a public archive for
observational data. Many of these result from the great variety of
relations between the various objects in the database, as well as from
the many properties that can be assigned to each one. In practice,
most users are interested in the properties of dark matter halos and
galaxies, objects created from the simulation output through
post-processing. Dark matter halos are the basic nonlinear units of
the simulated universe. They have properties such as mass, size and
position, in addition to internal substructures (subhalos) which are
the remnants of objects which fell into them during their growth. The
Millennium Archive contains information for about 750 million halos
and subhalos, all linked in a tree structure which describes how each
object was built from those present at the immediately preceding time.
This is the data structure used by the galaxy formation algorithms.
Galaxy formation is a complicated and uncertain process, and many
physical models for its various aspects must be tried in order to
establish those which best describe observed phenomena. A principal
goal of the Millennium Run project is to provide a framework for
comparing different galaxy formation models to observational data. It
is thus important to make available simulated galaxy catalogues with a
variety of assumptions about the physics of galaxy formation so that
users can get a feel for the uncertainties involved. A galaxy
catalogue for the full Millennium Run has about 1 billion entries. For
each of these galaxies many properties can be calculated by the
formation model and must be stored in the database.
In addition, pointers are
needed to connect the galaxies present at different times, and these
produce a tree data structure which gives the merger history of each
galaxy and which parallels (but is different from) the halo formation
trees.
An important issue which has to be addressed comes from the fact that
users wish to use the Millennium Run for a wide variety of purposes
and the view of the data which is most convenient for them depends
on their project. This requires that the data be delivered in a manner
that is more flexible than the traditional download of "flat files".
To this end the MPA/MPE/GAVO group decided to use a relational
database for storing the post-processing results of the Millennium
database. The main reason for this choice is that relational databases
support a flexible and intuitive query language (SQL), which allows
users to select out those objects that are of interest, in a form of
their own choice and without requiring knowledge of the physical
storage of the data. In the database this language is implemented by
efficient query engines that interpret the potentially complex
requests and execute these in the most efficient way.
Online access to the Millennium database is provided through a
 web-based query interface
(see Fig. 1). Apart from
providing documentation and example queries, users can type in their
own SQL queries and execute them. The results can be directly returned to
the user, they can be plotted online (see Fig. 2), or they can
be stored for further analysis in a private database, that is assigned
to registered users. This approach is directly modelled on the highly
successful SDSS SkyServer database
(http://cas.sdss.org/dr6/en/).
At the time of writing there are over 160 registered users of the
Millennium Archive site with local disk space allocated for storage
and manipulation of the results of their queries. About 80% of these
have successfully executed queries on the main databases. Roughly half
appear to be already carrying out significant research programmes
(more than 50 successful queries), while about 20% can be
characterised as heavy users (more than 1000 successful queries).
On average over 500 million rows of data are being downloaded from the
site per week. The user group is still growing rapidly and it will
probably be several years before the archive's success in generating
new science from the Millennium Simulation can be properly assessed. web-based query interface
(see Fig. 1). Apart from
providing documentation and example queries, users can type in their
own SQL queries and execute them. The results can be directly returned to
the user, they can be plotted online (see Fig. 2), or they can
be stored for further analysis in a private database, that is assigned
to registered users. This approach is directly modelled on the highly
successful SDSS SkyServer database
(http://cas.sdss.org/dr6/en/).
At the time of writing there are over 160 registered users of the
Millennium Archive site with local disk space allocated for storage
and manipulation of the results of their queries. About 80% of these
have successfully executed queries on the main databases. Roughly half
appear to be already carrying out significant research programmes
(more than 50 successful queries), while about 20% can be
characterised as heavy users (more than 1000 successful queries).
On average over 500 million rows of data are being downloaded from the
site per week. The user group is still growing rapidly and it will
probably be several years before the archive's success in generating
new science from the Millennium Simulation can be properly assessed.
Gerard Lemson and Simon White
Further information:
The public databases and documentation can be found at
 http://www.mpa-garching.mpg.de/millennium
and
http://www.g-vo.org/Millennium http://www.mpa-garching.mpg.de/millennium
and
http://www.g-vo.org/Millennium
|